
HPC workloads on Robin Cloud Native Platform (CNP) using Nvidia GPU (MIG A100)



In today’s world, graphics processing units or GPUs have attracted a lot of attention as the optimal vehicle to run artificial intelligence (AI), machine learning (ML) and deep learning (DL) workloads. These workloads require massive amounts of data, both ultra-high speed and parallel processing, along with flexibility and high availability. It is clear that high-performance computing (HPC) with graphics processing unit (GPU) systems are required to support cutting-edge workloads. Therefore, our cloud platforms must be enhanced to get the most out of them.
Challenges of managing GPU HPC workloads addressed by Robin CNP
- GPUs are very expensive to procure and maintain. Thus, efficient management plays a crucial role in getting the most out of those resources. Cutting-edge Kubernetes platforms, such as Robin.io Cloud Native Platform, provide access to hardware resources, such as Nvidia GPUs, network interface cards (NICs) and InfiniBand adapters. However, configuring and managing nodes with these hardware resources requires configuration of multiple software components, such as drivers, plugins, container runtimes or other libraries, all of which are complex and are prone to errors.
- Dependencies with GPU drivers,CUDA drivers (CUDA once stood for compute unified device architecture but this expansion has been dropped) and partition scheduling requires a certain level of technical expertise and involves a lot of manual operations. On legacy Kubernetes platforms, this means a lot of manual hunting and hardcoding.
- NVIDIA MIG GPU supports fractional GPUs where a single A100 GPU can be fractionated into multiple partitions of smaller GPU instances. Managing, scheduling and accounting these resources requires a hyper-GPU-aware cloud-native platform that can orchestrate the application and GPU allocations.
- Accounting and chargeback reports of GPU resources is vital for managing a large GPU infrastructure to make sure your return on investment (ROI) is achieved especially when these resources are shared by multiple applications and teams.
- Ease of provisioning of the entire GPU application stack including its dependent libraries, drivers such as CUDA, TensorFlow, PyTorch, JupyterHub, Caffee, Keras Theano, Python and GPU drivers. Robin policies will autodiscover, autoselect and configure the resources for you, across numerous lifecycle events and changes – no hunting and no hardcoding required.
- Cloud-native GPU workloads, transformation of legacy systems into cloud-native involves containerizing your HPC workloads using Kubernetes orchestration and attaining DevOps, MLOps capabilities without compromising on the management and scheduling of GPU workloads.
Support for VM-based workloads: Robin.io Cloud Native Platform supports both containers and VMs simultaneously, even on the same worker node.
Observability: As the infrastructure and the application demand increase over a period of time, the typical day 2 operational challenges tend to surface and managing the HPC workloads effectively becomes the utmost important task for the SRE and Ops teams. A proper observability stack, like Prometheus or Grafana must be built into the platform. Furthermore, Robin’s Sherlock allows you to plane and observe those what-if scenarios for cluster, application, server and network failures, among others.
Running your HPC K8s workloads on Robin CNP
Robin CNP orchestrates GPU, CPU, storage and network intensive cloud-native workloads at scale, for stateful and stateless applications.
Robin CNP installation by default installs the Nvidia GPU operator and the required Nvidia drivers, automatically discovers the GPU resources that are attached to the host, and manages the allocation and deallocation of resources.
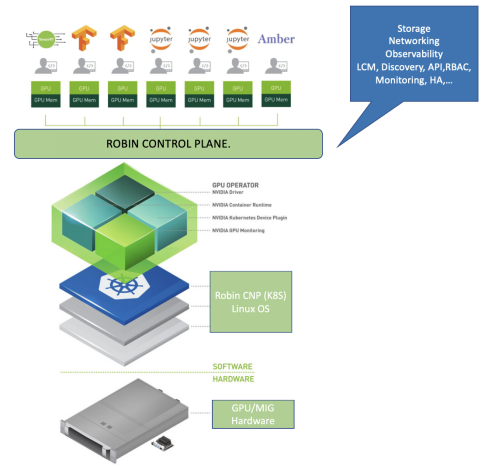
Robin CNP supports Nvidia MIG A100 GPU (multi-instance-GPU) and provides interfaces to partition the MIG GPU into various profiles and makes it easy for the end-users to selectively choose fractional GPU for their workload needs as shown below.
CNP ships with numerous packaged application bundles like PyTorch, TensorFlow, Python, Keras, Cafee, Jupyter, and JupyterHub that data science teams can start using on day 1. Each of these has built-in lifecycle automation policies. Furthermore, any application can be easily ingested with a helm chart.

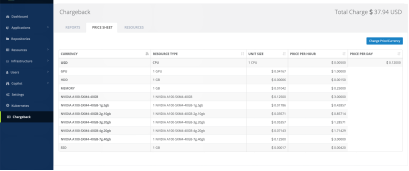
Chargeback & accounting
CNP comes with a rich, highly customizable chargeback reporting framework with role-based access control that ensures ROI is attained.
Shared and persistent storage
Robin Cloud Native Storage (CNS), that comes as a part of Robin CNP, supports stateful and stateless applications with industry-leading performance. It provides application topology data services (data, config, metadata, secrets) such as snapshots, backup, clones, QoS, replication, encryption, compression, data rebalancing and complex service level management dependencies. CNS supports all major Kubernetes distributions: Robin CNP, Anthos, OpenShift, Rancher, AKS, EKS, GKE and open source, to name a few.
Here is a quick demo of a simple neural network workload using GPU on Robin CNP:
Conclusion
Robin CNP is a GPU-aware cloud-native platform that radically simplifies the provisioning and lifecycle management of compute-heavy GPU workloads. Furthermore, Robin CNP provides these advantages using an intuitive, declarative interface, with advanced automation, that reduces deployment complexity, timelines and human error. You simply tell CNP what resources to include, then CNP builds a reusable policy, models all of the resource configurations and auto-configures them for you, across the service’s entire life-cycle-instantiate, start, stop, migrate, scale and delete.