Self Service AI/ML & Big Data on Kubernetes
Cloud-native AI/ML for Your Enterprise
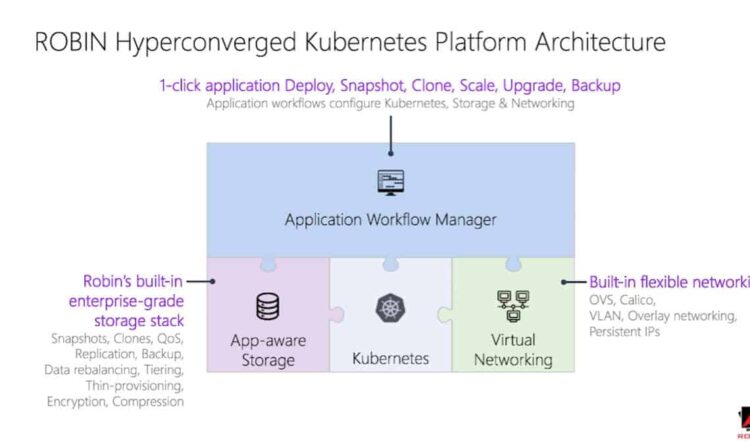
The Robin Cloud Native Platform extends Kubernetes with application automation, built-in storage, and networking, to deliver a production-ready solution for AI/ML. Robin automates the provisioning and management of AI/ML clusters so you can deliver an “as-a-service” experience with one-click simplicity to data engineers, data scientists, and developers.











Use cases
Separation of compute and storage
Disaggregate compute and storage, the cloud-native way
Enjoy cloud-like cost efficiencies by disaggregating compute and storage. Scale independently so you can store massive data on inexpensive hardware, while only utilizing compute when needed. For high performance, turn on data locality with one click.


Improved hardware utilization
Get more out of your hardware investments
Consolidate multiple AI/ML workloads and improve hardware utilization without compromising SLAs or QoS. The Robin platform provides multi-tenancy with RBAC which enables sharing resources between clusters. For example, if a cluster runs the majority of its batch jobs during the night, it can borrow resources from an adjacent application cluster with daytime peaks, and vice versa.
Self-service experience
Self-service provisioning in an app-store experience
Create a private app-store that your developers can use to provision AI/ML clusters, eliminating IT tickets and procedural delays. Robin’s application automation platform simplifies the deployment of complex, AI/ML applications on Kubernetes. Simply log in to an app-store experience, click on the desired application, and allocate the compute and storage resources. Your application will be deployed and ready to use within minutes.