Automate Complex Enterprise Applications


Robin Platform Datasheet
Automate Enterprise Applications on Kubernetes
Extend Kubernetes for data-intensive applications such as Oracle, Cloudera, Elastic stack, RDBMS, NoSQL, and other stateful applications.
Robin Platform
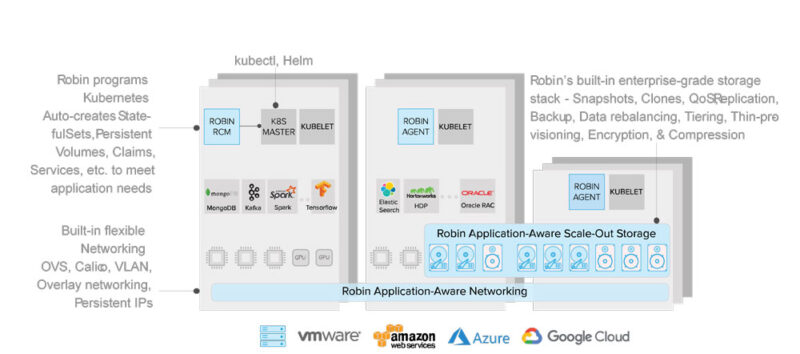
Robin is a Software Platform for Automating Deployment, Scaling and Life Cycle Management of Enterprise Applications on Kubernetes. Robin provides a self-service App-store experience and combines containerized storage, networking, compute (Kubernetes), and the application management layer into a single system.
Robin.io helps enterprises increase productivity, lower costs – CAPEX and OPEX, and enables always-on automation with technology solutions for big data, databases, indexing and search, and industry solutions for financial services and telco.
This software-only solution runs on-premises in your private data center or in public-cloud (AWS, Azure, GCP) environments and enables 1-click deployment of any application. Robin enables 1-click simplicity for lifecycle management operations such as snapshot, clone, patch, upgrade, backup, restore, scale, & QoS control of the entire application. Robin solves fundamental challenges of running big data & databases in Kubernetes & enables deployment of an agile & flexible Kubernetes-based infrastructure for Enterprise Applications.
Key Benefits
- Increase Productivity
- Lower Cost – CAPEX and OPEX
- Gain Always-on Availability
- Run data-heavy applications on Kubernetes
Robin Platform Stack Components
Application Management Layer – Manage Applications and configure Kubernetes, Storage & Networking with Application workflows.
Kubernetes – Run big data and databases in extended Kubernetes, eliminating limitations that restrict Kubernetes to micro-services applications.
Built-in Storage – Allocate storage while deploying an application or cluster, share storage among apps and users, get SLA guarantees when consolidating, support for data locality, affinity, anti-affinity and isolation constraints, and tackle storage for applications that modify the Root filesystem.
Built-in Networking – Set networking options while deploying apps and clusters in Kubernetes and preserve IP addresses during restarts.
Features |
Benefits |
Rapid Deployment – Self-service 1-click | Slash deployment and management times from weeks and hours to minutes. Deploy and manage data-heavy apps and services in Kubernetes. |
Control QoS – Dynamic control QoS for every resource – CPU, Memory, Network and Storage. | Get complete visibility into the underlying infrastructure, set min and max IOPs, eliminate noisy neighbor issue, and gain performance guarantee. |
Rapid clones – Clone the entire application along with its data – thick, thin, or deferred. | No performance penalties, backup data with ease, share data among users and applications, among dev, test, and prod, with no additional storage. |
Application Snapshots – Take unlimited full application cluster snapshots, which include application configuration + data | Restore or refresh a cluster to any point-in-time using snapshots. Roll back easily with 1-click to the last snapshot in case of data corruption. |
Scale – Decouple compute and storage, | Scale out – add nodes. Scale up – increase CPU, Memory and IOPs. |
High Availability – No single point of failure – get reliable crossover and detect failures. | Get automatic App-aware data failover for complex distributed applications on bare metal – Robin is the ONLY product to provide HA for apps that persist state inside Docker images. |
Upgrade – Automated rolling upgrade of application containers that is integrated with | Safe-Upgrade technology guarantees that failed upgrades can be rolled back without disrupting the application. |
Enterprise Data Apps-as-a-Service – Sample Customer Deployments
Fortune 500 Financial Services Leader
- 11 billion security events ingested and analyzed in a day
- DevOps simplicity for Elasticsearch, Logstash, Kibana, Kafka
Global Networking and Security Leader
- 6 Petabytes under active management in a single Robin cluster
- Agility, consolidation for Cloudera, Impala, Kafka, Druid
Global Technology Company – Travel Industry
- 400 Oracle RAC databases managed by a single Robin cluster
- Self-service environment for Oracle, Oracle RAC