Robin Storage: Advanced Data Management for Google Kubernetes Engine (GKE) | Solution Brief


Use the preferred storage for GKE to run mission-critical stateful applications on your Kubernetes. Bring advanced data management to Kubernetes-native frameworks including HELM and Operators.
The Need For Data Management
Stateful applications such as PostgreSQL, MySQL, MongoDB, Elastic Stack, Kafka, and MariaDB
require advanced data management capabilities in order to:
- Release products on schedule: Automated lifecycle management for app+data (not just the
storage) is required to save valuable time at each stage of the lifecycle. Multiple teams (Dev/
Test/Ops) need a mechanism to collaborate without procedural delays. - Recover from system failures: App+data protection capabilities such as point-in-time
snapshots, backup, and restore are required to recover from system failures and user errors. - Avoid infrastructure lock-in: The ability to migrate from on-prem to cloud and vice versa, and
among the public clouds is needed to avoid infrastructure lock-in. - Deliver predictable performance: To guarantee QoS and to ensure high priority applications
do not miss SLAs, you need the ability to set IOPS limits per app. - Eliminate security vulnerabilities: Enterprise-grade security is required with authentication and
encryption to ensure your data is safe.
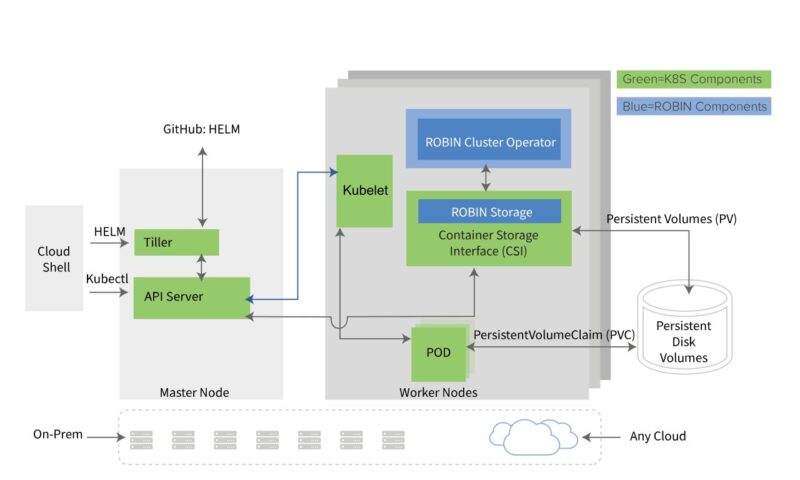
Robin Storage – Advanced Data Management for
Kubernetes
Robin Storage is a purpose-built container-native storage solution that brings advanced data management capabilities to Kubernetes. It provides automated provisioning, point-in-time snapshots, backup and recovery, application cloning, QoS guarantee, and multi-cloud migration for stateful applications on Kubernetes.